中國火爆的AI大模型公司
deepseek徹底引爆全球
引起矽谷震動

就在華爾街周一緊張評估「DeepSeek風暴」之際,這家中國公司再度甩出新品!
在圖像生成基準測試中超越OpenAI「文生圖」模型DALL-E 3的多模態大模型Janus-Pro,同樣也是開源的。
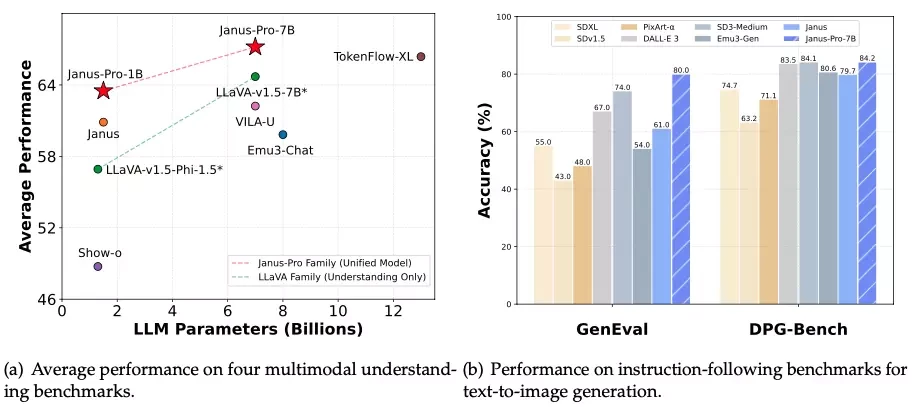

公司也在報告中,給出了更多圖像生成的案例。
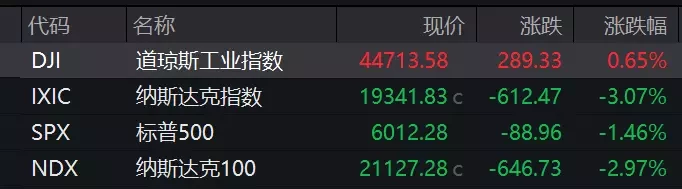
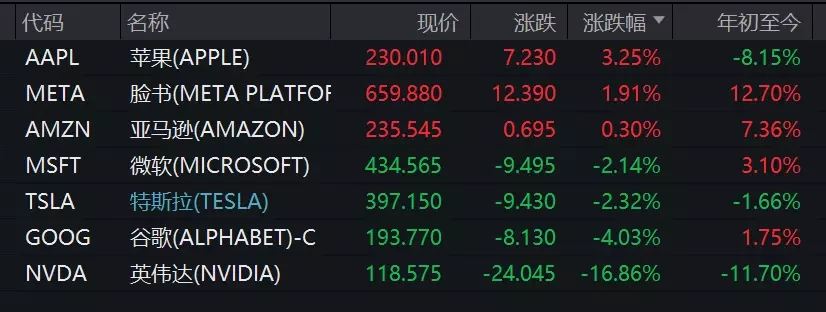
1月28日,美股三大指數收盤漲跌不一。科技股表現分化,英偉達等半導體板塊暴跌16.86%,市值蒸發5888.62億美元(約合人民幣4.27萬億元)。
DeepSeek新模型以低成本實現高性能,引發市場對科技巨頭估值擔憂。該模型登頂美中應用下載榜,性能強成本低,對全球算力衝擊巨大。
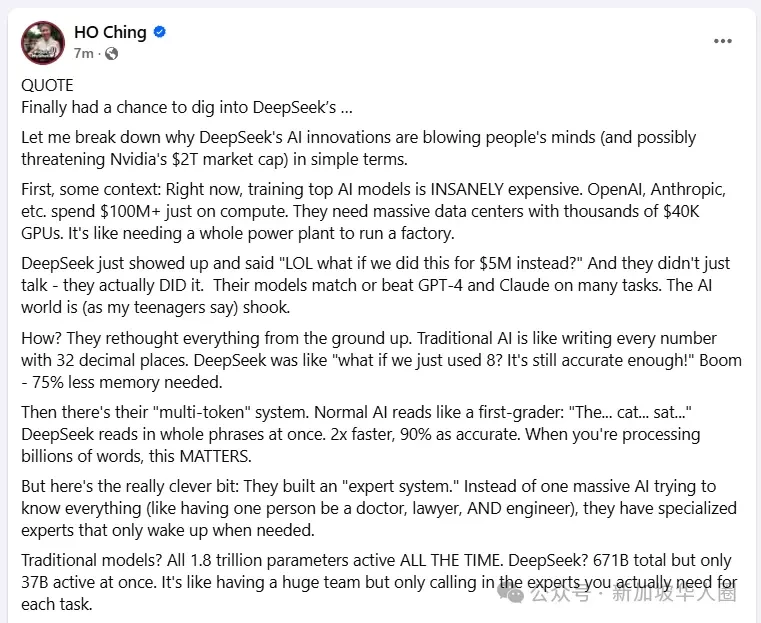
新加坡前總理李顯龍妻子何晶,對DeepSeek最新的解釋(原文翻譯): 終於有機會深入了解DeepSeek的…… 讓我用簡單的語言來剖析一下DeepSeek的人工智慧創新為何令人驚嘆(甚至可能威脅到英偉達2萬億美元的市值)。
首先,一些背景情況:目前,訓練頂尖人工智慧模型的成本高得離譜。OpenAI、Anthropic等公司僅計算方面就花費1億多美元。它們需要配備數千個價值4萬美元的圖形處理器(GPU)的大型數據中心。這就好比運行一個工廠需要一整座發電廠。
DeepSeek出現了,他們說:「哈哈,如果我們只花500萬美元來做這件事呢?」而且他們不只是說說而已,是真的做到了。他們的模型在許多任務上與GPT - 4和Claude不相上下甚至更優。人工智慧界(就像我那些十幾歲的孩子說的那樣)被震撼了。 怎麼做到的呢?他們從根本重新思考了一切。傳統人工智慧就像是用32位小數來寫每個數字。
DeepSeek則像是說:「要是我們只用8位小數呢?準確性仍然足夠!」結果——所需內存減少了75%。 然後是他們「多標記」系統。普通人工智慧閱讀起來像一年級小學生:「那……只……貓……坐……在……」
DeepSeek能一次性讀取整個短語。速度是原來的兩倍,準確性達到90%。當要處理數十億個單詞時,這一點很重要。
但這裡真正巧妙的地方在於:他們構建了一個「專家系統」。不是讓一個龐大的人工智慧試圖知曉一切(就像讓一個人同時是醫生、律師和工程師),而是有專門的專家,只在需要的時候啟動。 傳統模型?1.8萬億個參數一直全部處於活躍狀態。
DeepSeek呢?總共6710億個參數,但一次只有370億個活躍。這就好比有一個龐大的團隊,但只為每項任務召集實際需要的專家。
結果是令人難以置信的:
- 訓練成本:從1億美元降至500萬美元
- 所需GPU數量:從10萬台降至2000台
- 應用程式編程接口(API)成本:降低95%
- 可以在遊戲GPU上運行,而不需要數據中心硬體 「但是等等,」你可能會說,「肯定有陷阱!」這就是瘋狂的地方——這一切都是開源的。任何人都可以檢查他們的工作。代碼是公開的。技術論文解釋了一切。這不是魔法,只是極其巧妙的工程設計。
為什麼這很重要呢?因為這打破了「只有大型科技公司才能涉足人工智慧」的模式。你不再需要價值10億美元的數據中心了。可能幾塊不錯的GPU就夠了。
對於英偉達來說,這很可怕。他們的整個商業模式建立在以90%的利潤率銷售超級昂貴的GPU上。如果突然每個人都能用普通遊戲GPU做人工智慧……嗯,你就明白問題所在了。
更關鍵的是:DeepSeek是用不到200人的團隊做到的。與此同時,Meta的團隊光是薪酬就超過了DeepSeek的全部訓練預算……而且他們的模型還不如DeepSeek的好。
這是一個典型的顛覆性創新故事:現有企業優化現有流程,而顛覆者重新思考根本方法。DeepSeek問的是「如果我們更聰明地做這件事,而不是單純投入更多硬體呢?」
其影響是巨大的:
- 人工智慧開發變得更易獲取
- 競爭大幅加劇
- 大型科技公司的「護城河」看起來更像是小水坑
- 硬體需求(和成本)急劇下降
當然,像OpenAI和Anthropic這樣的大公司不會坐以待斃。他們可能已經在實施這些創新了。但效率這隻精靈已經從瓶子裡出來了——不可能再回到「只管投入更多GPU」的做法了。
最後的想法:這感覺像是我們會回顧的一個轉折點。就像個人電腦使大型機變得不那麼重要,或者雲計算改變了一切。
人工智慧即將變得更加易獲取,成本也更低。問題不在於這是否會顛覆現有的參與者,而在於速度有多快?這也是全球市場下跌的原因之一。



資料參考 /21財經客戶端、DeepSeek官方網站、 財聯社、證券時報、Wind等 版權歸原作者所有,如有侵權請聯繫我們刪除























